
MCP Explained Part 6: Evaluation
The Blockscout MCP server is evaluated through automated testing and cross-agent benchmarking to measure not just accuracy, but how effectively LLMs like Claude, ChatGPT, and Gemini use its tools for real blockchain analysis.


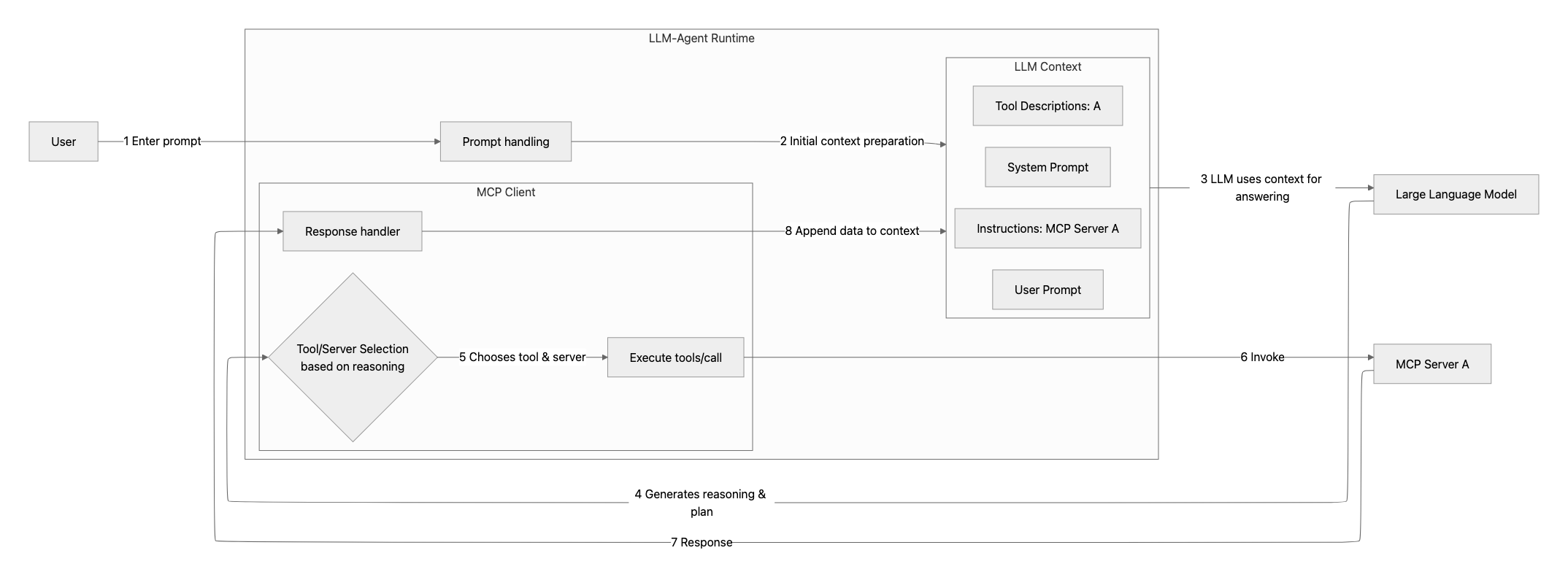
TL;DR: Evaluating an MCP server is more than checking whether tools return correct JSON. Each result emerges from the joint reasoning loop between an LLM and the server - planning, tool selection, pagination, and follow-ups all shape the final outcome.
To capture this complexity, the Blockscout MCP server is tested through two complementary methods: automated evaluation with Gemini CLI, which compares structured agent outputs against blockchain ground truth, and cross-agent benchmarking across Claude Desktop, ChatGPT, LeChat, and Gemini CLI.
Together, these approaches measure not just correctness, but how effectively different LLMs use the MCP ecosystem to perform real blockchain analysis.
MCP Explained - Index
Challenges in Evaluating MCP Servers
Simply checking that an MCP tool was invoked and returned the “right JSON” after an API call is not enough. An MCP server always operates within a loop involving the LLM and its agent: reasoning, planning, tool selection, pagination, and follow-up calls all influence the final output.
In other words, what you evaluate is not an isolated endpoint, but a reasoning-plus-tools ecosystem.
Why Full Evaluation is Hard
Nondeterministic tool calls
Invoking the same prompt within the same agent multiple times does not guarantee the same execution path. Some LLMs may decide to skip a call altogether or select a different tool, even if the input and environment are identical. The effect is especially strong for rare or narrowly scoped tools, which the model may overlook depending on its internal reasoning trace.
Free-form natural-language answers
Agents usually respond in open-ended text rather than structured data. Their phrasing, ordering of facts, and level of detail vary from run to run. This makes it difficult to define a clear algorithmic rule for “correctness”.
Uneven domain understanding
Different LLMs possess different mental models of blockchain data and operations. Some can correctly map tool descriptions to relevant analytical steps, while others fail to recognize the connection.
Dependence on agent-level instructions
System prompts and runtime policies strongly affect exploration depth. One agent may iterate through multiple tool calls, fetching several pages of results to build a comprehensive view. Another may stop early, summarize partial data, and request user confirmation.
As a result, the breadth and reliability of blockchain analysis vary widely even with the same underlying MCP server.
Using multiple MCP servers
Another complication arises from using multiple MCP servers simultaneously. When several servers expose tools with similar names or overlapping descriptions, interference may occur - the model can confuse their purposes or combine tool calls from different servers unpredictably.
However, such cross-server interactions were deliberately excluded during the design stage of the Blockscout MCP server. Its instruction set and tool descriptions were developed under the assumption of operating in isolation, without considering environments where multiple MCP servers coexist.
Meaningful Testing
For the Blockscout MCP server, meaningful testing should be performed only within agents that realistically represent user scenarios. While environments such as Cursor or Claude Code make sense for developer workflows, most end users are expected to interact through general-purpose chat platforms like Claude.ai, ChatGPT, or LeChat, since blockchain analysts are not necessarily programmers.
The first integration tests were conducted in Claude Desktop in June 2025, when it was the only general-purpose agent allowing MCP configuration. The evaluation revealed that Claude Desktop ignored the server-side instruction set during initialization.
To address this, a technical placeholder tool __unlock_blockchain_analysis__ was added (see Part 8: Server instructions). After this adjustment, the agent was able to complete the entire testing suite.
Automated MCP Evaluation via Gemini CLI
Manual checks of the MCP server are fine for one-off experiments, but they don’t scale. Any change to server instructions, tool descriptions, or response formats forces you to repeat the same scenario in an agent UI.
A reproducible way to run the same prompts is needed, capture an agent’s step chain (reasoning → tool choice → pagination → follow-ups), and compare the result with a ground truth.
This matches the idea that an MCP server is not an “isolated endpoint,” but a “reasoning + tools” ecosystem where the outcome depends on the model’s plan and the server’s guidance.
Why Gemini CLI
As the “engine,” Gemini CLI was chosen because it:
- Lets us query Gemini 2.5 Pro at this stage of the MCP server development without paying for tokens;
- Works as a command-line tool (good for scripts and integrating with other agents);
- Can override system instructions, which could in the future help when the default “coder” frame blocks blockchain-analysis behavior.
Unified agent output format
To check answers automatically, we standardize how the agent returns results. The agent prints JSON with three parts: the original query, a step-by-step trace, and the final answer.
This format is inspired by Schema Guided Reasoning: the structure guides the model and simplifies parsing. The final value must be a simple, easy-to-parse form - a number, a transaction hash, a list of values, or another basic data structure - not a free-form paragraph.
This makes automatic verification and comparison with ground truth straightforward.
{
"original_query": "The exact user question/request",
"steps": [
// Array of analysis steps - see step types below
],
"response": {
"final": "Simple parseable answer OR null if is_error is true",
"is_error": false,
"error_type": null,
"confidence": "high|medium|low",
"comments": "Detailed explanation supporting the final answer or error description"
}
}
Each steps item is one of three types.
web search
{
"type": "web_search",
"data": {
"query": "search terms used",
"result_summary": "Key findings from the search",
"status": "success|error"
}
}
tool call
{
"type": "tool_call",
"data": {
"tool": "exact_tool_name",
"args": {actual_parameters_passed},
"result_summary": "Brief description of what the tool returned",
"status": "success|error"
}
}
reasoning
{
"type": "reasoning",
"data": {
"text": "Clear explanation of your reasoning, what you need to do next, or analysis of previous results"
}
}
Ground Truth Methodology
The idea is as follows:
- The evaluation system holds a set of prompts for Gemini CLI and a “source of truth” for each prompt:
- a static value - if the fact is stable (for example, the address for a given ENS name);
- a Python script - for all other cases. The script pulls data directly from blockchain/Blockscout to form the current ground truth.
- Prompts are written to minimize drift between running the script and calling the model.
- For each prompt we run:
- Gemini CLI:
gemini -p "query"(we expect the JSON above on stdout); - a parser that extracts
response.finaland compares it with ground truth.
- Gemini CLI:
- If they do not match, we analyze only what’s available in steps - the short
result_summaryfor each call - to see which tools ran and which intermediate conclusions the agent made. - Each prompt can be repeated several times to record repeatability.
- The result is a report showing how well Gemini CLI, with the current MCP server version, can analyze blockchain activity. Comparing two reports lets us see how changes in MCP instructions, tool descriptions, or tool output formats affect the agent’s analysis quality.
Current progress
We have a base set of 14 prompts that checks two things:
- each MCP tool is distinguishable and callable by the agent in a real session;
- the tool’s response structure is correctly “understood” by the model (including pagination and notes).
What’s next
If this testing approach proves successful, we can build a benchmark on top of it to show how well agents can analyze blockchain activity.
Comparative Testing Across LLM Agents
Beyond the automated evaluation plans, in mid-October 2025 we ran a manual check of how different general-purpose agents reason about on-chain activity:
- Claude Desktop (Sonnet 4.5, Extended Thinking)
- ChatGPT Web (GPT 5 Extended Thinking), MCP Server enabled via developer mode
- LeChat (Think)
- Gemini CLI (Gemini 2.5 Pro)
☝ Strictly speaking, Gemini CLI is not a general-purpose agent, but neither Gemini Web nor Google AI Studio lets you configure an MCP server.
Method
- Separate projects were created in Claude Desktop and ChatGPT with the following special instructions:
You are a senior analyst specializing in Ethereum-blockchain activities with almost ten years of experience. You have deep knowledge of Web3 applications and protocols.
Each prompt was run in a new chat inside the project.
- In LeChat, each prompt was prefixed with the same phrase; every new prompt started a new chat.
- For Gemini CLI we used a
GEMINI.mdfile with instructions equivalent to Blockscout X-Ray; each prompt ran in a new session.
Scoring legend
- OK: correct and complete answer;
- FAIL: incorrect;
- NA: the agent did not propose a workable plan / did not finish the task.
Evaluation results
| Prompt | Claude Desktop | Chat GPT | LeChat | Gemini CLI |
|---|---|---|---|---|
| What is the block number of the Ethereum Mainnet that corresponds to midnight (or any closer moment) of the 1st of July 2025. | OK | OK | NA | OK |
What address balance of ens.eth? |
OK | OK | OK | FAIL |
Is any approval set for OP token on Optimism chain by zeaver.eth? |
OK | OK | OK | OK |
Tell me more about the transaction 0xf8a55721f7e2dcf85690aaf81519f7bc820bc58a878fa5f81b12aef5ccda0efb on Redstone rollup. |
OK | OK | OK | FAIL |
| What is the latest block on Gnosis Chain and who is the block minter? Were any funds moved from this minter recently? | OK | OK | FAIL | OK |
| Is there any blacklisting functionality of USDT token on Arbitrum One? | OK | OK | OK | OK |
Get the usdt token balance for 0xF977814e90dA44bFA03b6295A0616a897441aceC on the Ethereum Mainnet at the block previous to the current block. |
OK | OK | OK | OK |
Which methods of 0x1c479675ad559DC151F6Ec7ed3FbF8ceE79582B6 on the Ethereum mainnet could emit SequencerBatchDelivered? |
OK | OK | OK | OK |
| What is the most recent completed cross chain message sent from the Arbitrum Sepolia rollup to the base layer? | OK | OK | FAIL | OK |
How many different stablecoins does 0x99C9fc46f92E8a1c0deC1b1747d010903E884bE1 (Optimism Gateway) on Ethereum Mainnet hold with balance more than $1,000,000? |
OK | OK | NA | OK |
Make comprehensive analysis of the transaction 0x6a6c375ea5c9370727cad7c69326a5f55db7b049623fba0e7ac52704b2778ba8 on Ethereum Mainnet and give a one-word category. Collect as many details as possible. |
OK | OK | OK - but basic | OK - but basic |
How many tokens of NFT collection "ApePunks" owned by 🇵🇱pl.eth on Ethereum Mainnet? |
OK | OK | FAIL | OK |
How old is the address 0xBAfc03eC2641b82ae5E4c4f6cc59455773092DC6? |
OK | OK | NA | OK |
Take a look at the source code of the contract 0x3d610e917130f9D036e85A030596807f57e11093 on the Gnosis Chain and explain the difference between claim and claimTo. |
OK | OK | FAIL | FAIL |
| Check 5 most popular EVM-based chains available on Blockscout to see where FET token is deployed. Think deeply to ensure every defined token is official, and double-check your reasoning. | OK | OK | FAIL | OK |
|
Here is info about dex pools trading FET tokens: 1. FET/WETH - Uniswap V3 (1% fee) Pool Address: 0x948b54a93f5ad1df6b8bff6dc249d99ca2eca052Platform: Uniswap V3 2. FET/ETH - Uniswap V4 (0.3% fee) PoolManager Address: 0x000000000004444c5dc75cB358380D2e3dE08A90Pool ID: 0x80235dd0d2b0fbac1fc5b9e04d4af3e030efd2b1026823affec8f5a6c9306c38Platform: Uniswap V4 What are the latest 2 trades in each pool? Compose a table showing: trade date, direction FET→ETH or ETH→FET, volume in FET, volume in ETH/WETH, tx hash. |
OK | OK | FAIL | FAIL |
Notes and observations
- On the seemingly trivial prompt “What address balance of
ens.eth?” Gemini CLI converted wei → ETH incorrectly and showed a wrong balance. - While exploring the Redstone transaction, neither LeChat nor Gemini CLI tried to proactively detect the MUD-specific context of the tx (the domain context stayed “off-screen”).
- For the question about funds moved by a Gnosis Chain validator, LeChat ignored ERC-20 transfers and looked only at native transfers.
- In the cross-chain message task, LeChat did not propose a workable strategy to fetch them.
- In the NFT count for
🇵🇱pl.eth, LeChat dropped the flag emoji during ENS → address resolve, so it failed to find the hash. - Both LeChat and Gemini CLI misinterpreted the
claimTofunction during contract analysis.