
MCP Explained Part 1 : Introduction
The Blockscout MCP server uses the Model Context Protocol to give AI agents streamlined, reliable access to blockchain data without parsing complex UIs or large APIs, balancing simplicity, context, and usability.


TL;DR: AI agents are becoming important consumers of blockchain data, but parsing complex web UIs is inefficient and unreliable.
Instead of exposing the entire Blockscout database or all 150+ API endpoints, we propose a lean Model Context Protocol (MCP) server with a carefully chosen set of tools.
This approach balances expressiveness and simplicity, avoids context overload for LLMs, and makes blockchain data more accessible for everyday users and automated agents.
MCP Explained - Index
The Rise of AI Data Consumers
Blockscout is a platform that provides comprehensive access to blockchain data of different types and formats. This access is available both to regular users through the intuitive and functional Blockscout UI, and to numerous applications and traditional bots through a specially designed and well-documented Blockscout API.
With the rapidly growing interest in and development of AI-powered agents in today’s technology ecosystem, these intelligent systems are gradually becoming full-fledged and highly important consumers of blockchain data, forming a new category of clients with unique requirements and capabilities.
AI agents with direct and optimized access to blockchain data can, in simple everyday cases, effectively answer common user questions in text format, such as: “what exactly happened with my transaction,” or “how has my cryptocurrency balance changed significantly over the last day/week/month.”
In more complex cases, such intelligent agents can independently generate detailed compliance reports, carefully investigate cross-chain transfers of different crypto assets, actively support developers of Web3 applications and new distributed systems in deep analysis of network activity, and detect potential problems or anomalies.
It is obvious that AI agents could, in theory, access the data they need through the standard Blockscout UI, just like regular users. However, this inevitably raises a natural question: how effectively can modern LLMs, which power such agents, actually perceive and process a rendered web page with detailed information about a transaction or address?
This problem becomes particularly acute if such a page contains multiple tabs with a complex structure, or if critically important core information is displayed on the main screen while additional but equally important details are hidden in interactive expandable sections that require user interaction.
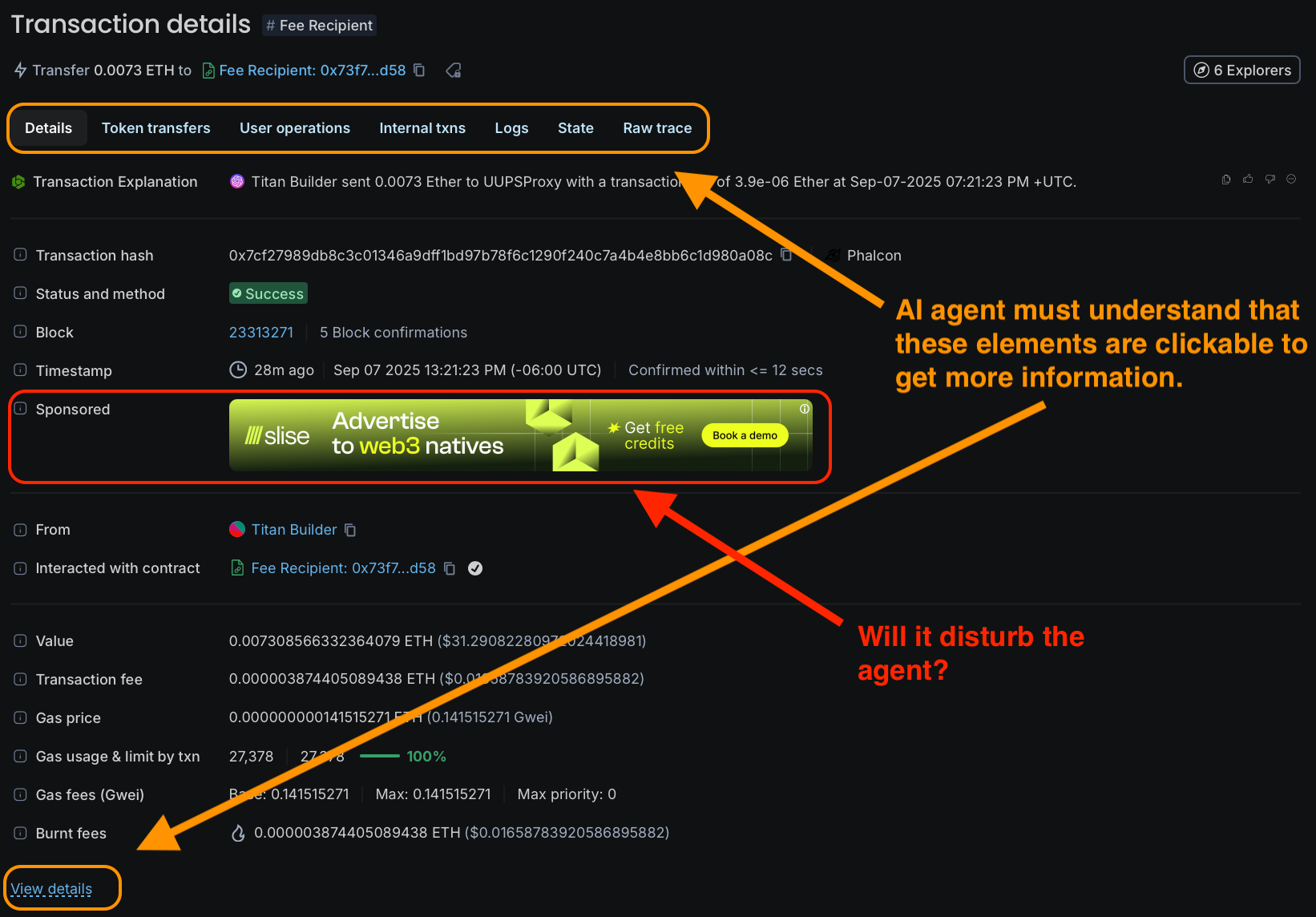
A much more convenient and technically justified way for AI agents is to obtain all the necessary information directly from an optimized database or through a specialized API interface.
Data presented in such a structured format is far better organized, semantically enriched with relevant information, and contains significantly less distracting and irrelevant content that could negatively affect analysis quality.
This is an undeniable and indisputable advantage in practical use for modern LLM agents, for whom such clearly structured information is much more preferable by their very nature and architectural features (including symbolic data analysis, attention mechanisms, context window limitations, and other technical aspects of their functioning).
Enabling AI Agents with Model Context Protocol
We decided to build a proof of concept to demonstrate how AI agents can analyze blockchain data. It is clear that creating your own agent is a costly task, associated with many risks: choosing the right LLM model, the inability to control degradation due to changes on the LLM provider’s side, preventing misuse (when users ask unrelated questions), and also paying the bills for token usage.
That is why we decided to allow any user or agent to integrate access to blockchain data directly into their usual workflows, for example in chat platforms.
Thanks to the Model Context Protocol, developed by Anthropic and already supported in many chat platforms and agentic software, implementing this functionality became possible with minimal effort. All that is needed is to create an MCP server that provides access to data stored in a Blockscout instance for different networks via MCP server tool calls.
Our first idea was not to develop our own solution.
Since Blockscout already has an API, it was logical to use a tool that could act as an API → MCP gateway, using the Higress MCP plugin for example. It allows you to describe simple logic in a YAML file for how responses from the API server are transformed into MCP server responses. At the same time, there is no need to deploy your own Higress Gateway - the configuration YAML file can be published on the official marketplace.
However, this approach has drawbacks. Adding new MCP tools or changing the arguments of existing ones requires a lengthy update process for the YAML file in the marketplace. The file itself has limitations in handling API requests (for example, see pagination in Part 2: Optimizations).
Analytics on tool calls also becomes unavailable, and providing access to data in multi-chain mode becomes overly complicated: a single MCP server would need to interact with multiple Blockscout instances for different networks. Although the first version of the plugin for Ethereum Mainnet was created, we decided to choose a path that gave us more independence in implementing the required functionality.
In addition to developing the protocol itself, Anthropic maintains open-source SDKs for building MCP clients and MCP servers. For the proof of concept, we chose the MCP Python SDK. The main factor in favor of the Python version of the SDK was that, when building the server, we planned to actively use AI coding assistants. For them, Python is a natural choice: it is widely supported, has a rich ecosystem of tools, and well-known libraries.
Moreover, during development it turned out that debugging the server on the Python SDK was much simpler than in other languages. Even without installing MCP Inspector, it is possible to test MCP server responses using a simple curl command.
curl --request POST \\
--url <https://mcp.blockscout.com/mcp> \\
--header 'Accept: application/json, text/event-stream' \\
--header 'Content-Type: application/json' \\
--data '{
"jsonrpc": "2.0",
"id": 3198234636006132,
"method": "tools/list"
}'
curl --request POST \\
--url <https://mcp.blockscout.com/mcp> \\
--header 'Accept: application/json, text/event-stream' \\
--header 'Content-Type: application/json' \\
--data '{
"jsonrpc": "2.0",
"id": 3657722677276604,
"method": "tools/call",
"params": {
"name": "get_latest_block",
"arguments": {
"chain_id": "7887"
}
}
}'
Providing Blockchain Data Access
The next step was to determine how exactly to provide access to blockchain data collected in Blockscout.
At first glance, the most obvious solution seemed to be allowing the MCP server to execute SQL queries directly on the database. Modern LLMs are capable of generating text-to-SQL queries, so the scheme would look like this: the MCP server provides the agent with descriptions of the tables in the Blockscout database, the agent converts the user request into one or more SQL queries, sends them to Blockscout via the MCP server, receives the results in tabular form, and then transforms them into user-friendly text.
The diagram below illustrates this simplified approach:
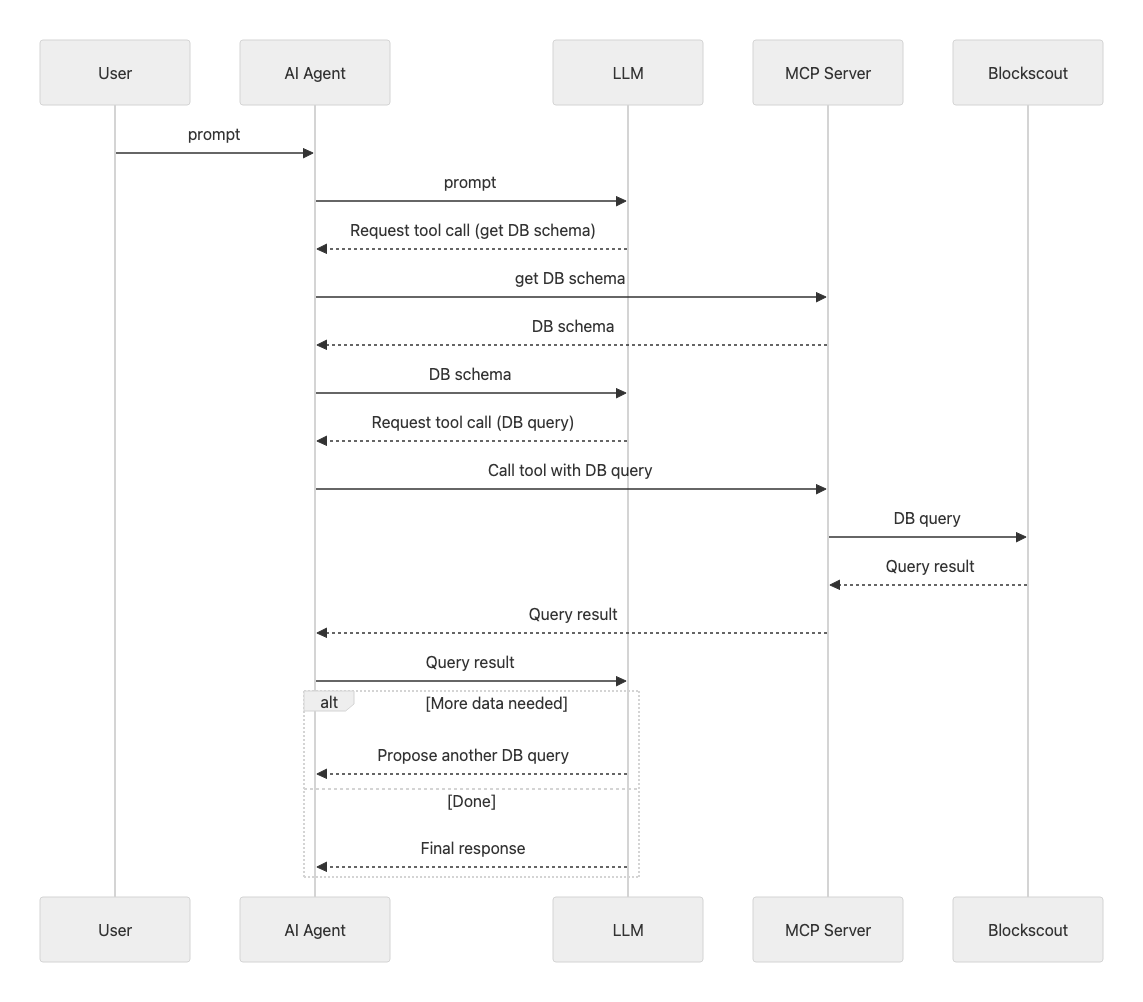
This approach to analyzing blockchain data is described in detail in the article “Can ChatGPT unlock blockchain data for the masses?.”
Although the article used an outdated version of GPT-3.5 with a small context window, the main conclusion remains relevant: with a large number of tables and fields, even if they are documented, the quality of the final SQL query directly depends on the quality of the initial user prompt. If the user does not specify exactly which data they need and how it relates to the DB structure, the model may generate an incorrect query and return either the wrong data or only part of it.
In the case of Blockscout, the situation was even more complicated.
At the time of MCP server development, the database tables were not fully documented. To work with more than 50 tables (and in the case of rollups or side-chains, around 60), it would have been necessary to manually describe each table, its fields, and relationships - with no guarantee that this would fully solve the problems described in the article.
In addition, some data (such as address metadata, ENS, and verified contracts) is not stored in the database but in separate microservices. Finally, for security reasons, direct external access to Blockscout’s databases and microservices is not provided.
The only public service capable of returning data in a DB-query-like form is the GraphQL endpoint of a Blockscout instance, but its schema is limited and does not cover all tables.
All these factors make direct SQL access through the MCP server an unrealistic solution for the Proof of Concept. Therefore, using existing Blockscout API instances turned out to be the more rational option:
- The full functionality of the UI is duplicated, since the UI itself retrieves data through the Blockscout API.
- The limited set of API endpoints simplifies the LLM’s choice of the right tool for a specific request.
- Data aggregation from different tables is performed automatically, avoiding the need to overload the context with descriptions of relationships.
- There is no need to manually maintain up-to-date database schemas on the MCP server side.
- There is no need to store separate database schemas for different rollups and side-chains.
MCP Server Initialization and Tool Context
Before moving on to the next topic, it is worth briefly explaining how exactly an AI agent interacts with the MCP server.
When initializing the MCP server, the agent requests all available tools, resources, and prompts. The first two are used by the agent itself, while prompts are intended for the user.
In this section, we will focus only on the tools.
For each tool, the MCP server provides its description, a list of parameters, and their characteristics. Recently, the option to specify the output data structure of a tool has also been introduced, but we will leave that aside for now.
These descriptions are needed by the LLM to decide when to call a tool, how to combine it with others, and how to build a chain of sequential calls. Therefore, the description must be sufficiently detailed and help the model “immerse” itself into the required domain to use the tool correctly.
It is important to note that descriptions of all tools are included in the LLM context (most often in the system prompt) for every user request. Here, an inevitable trade-off arises: the more tools and the more detailed their descriptions, the greater the agent’s functionality - but the less “working” context remains for reasoning and stable multi-step planning.
This increases the risk of truncating an important part of the prompt after inserting tool results and, as a consequence, misinterpreting the task in later steps.
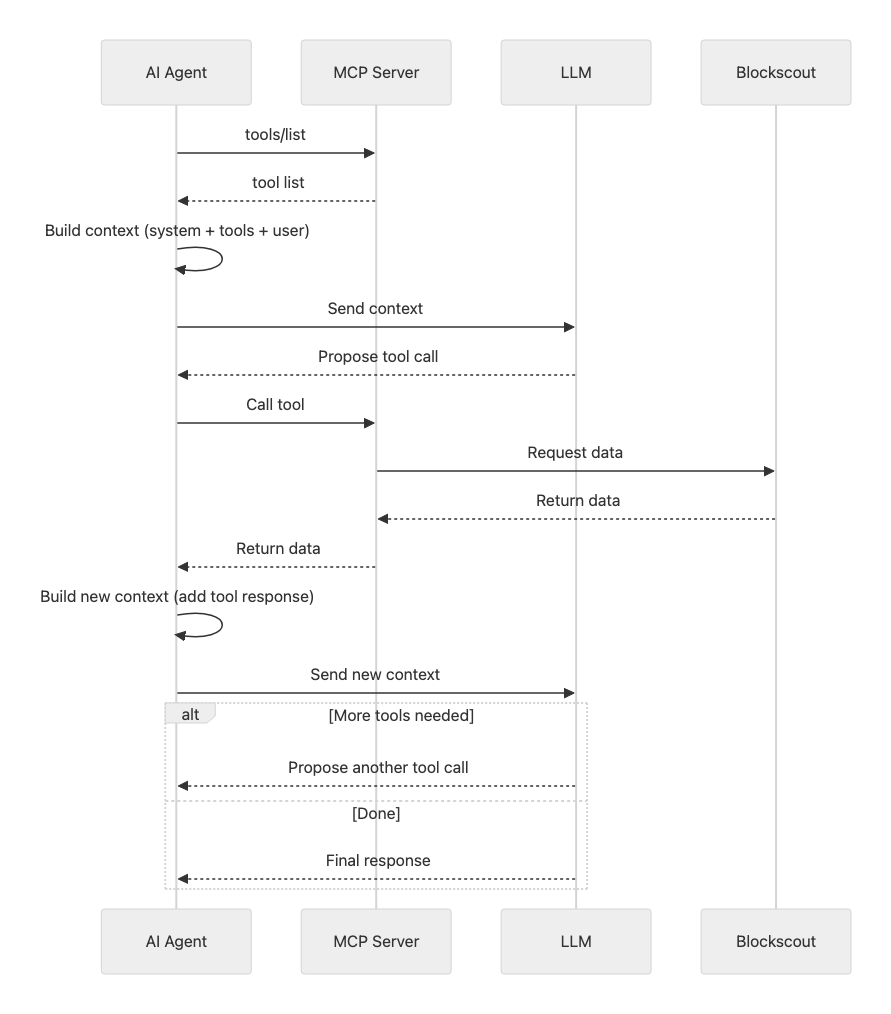
So, the MCP server imposes an “initialization cost” in the input context: part of the context window is consumed by tool metadata even before the agent starts working. This is a systemic trade-off: more tools ↔ less space for reasoning and stable planning.
In practice, this manifests as (1) truncation of useful context after inserting tool results, and (2) degradation of context in subsequent steps of the chain.
A Minimal Yet Sufficient Toolset
Blockscout API (version 2) contains more than 150 endpoints, and several dozen more are provided through proxying microservice APIs. From the conclusions of the previous section, it is clear that creating MCP server tools for every single endpoint would be impractical. This raises the question: which endpoints should be selected?
The initial set of tools for the Blockscout MCP server was chosen according to the following criteria:
- The number of tools should not be too large. The optimal limit is around 20.
- The set of tools should be sufficient to cover typical scenarios of blockchain activity analysis.
- Tools should not return simple lists of high-level entities (addresses, transactions, blocks) that are not connected by any common context. For example, a plain list of transactions is not very useful, but a list of transactions in a specific block makes sense.
- If the result of calling one endpoint (“A”) can be obtained through a combination of calls to several other endpoints (“B” and “C”), then endpoint “A” does not need to be implemented as a separate tool.
- Aggregating tools (such as token holders or statistics), while possibly the most appealing at first glance when getting familiar with the MCP server, are unlikely to be frequently used later on. In real usage, one rarely needs to know “how many transactions happened in the last 24 hours” or “who are the top 10 holders of token XX.”
Based on these criteria, the following minimal yet sufficient set of tools was formed:
get_address_by_ens_namelookup_token_by_symbolget_contract_abiinspect_contract_codeget_address_infoget_tokens_by_addressget_transactions_by_addressget_token_transfers_by_addresstransaction_summarynft_tokens_by_addressget_block_infoget_transaction_infoget_transaction_logsread_contract
Since the MCP server was expected to provide access to data from any network indexed by Blockscout, the tool get_chains_list was added to the list. It allowed the LLM to identify the required network before using other tools. More details in a separate section Part 3: Multichain.
In addition, the tool get_latest_block was included, since LLMs often require a reference point - the current block - in order to properly interpret the temporal context of “here and now” in the blockchain.
In the future, the tool direct_api_call is planned to be added. Details about it are provided in a separate section Part 7: Direct Api Calls.